Travaux méthodologiques sur l’enquête Budget de Famille
Modernisation de l’enquête budget des familles par utilisation d’outils de classification automatique
1 janv. 2022
| Recodification de la NACE 2.0 vers la NACE 2.1 avec des LLMs | |
|---|---|
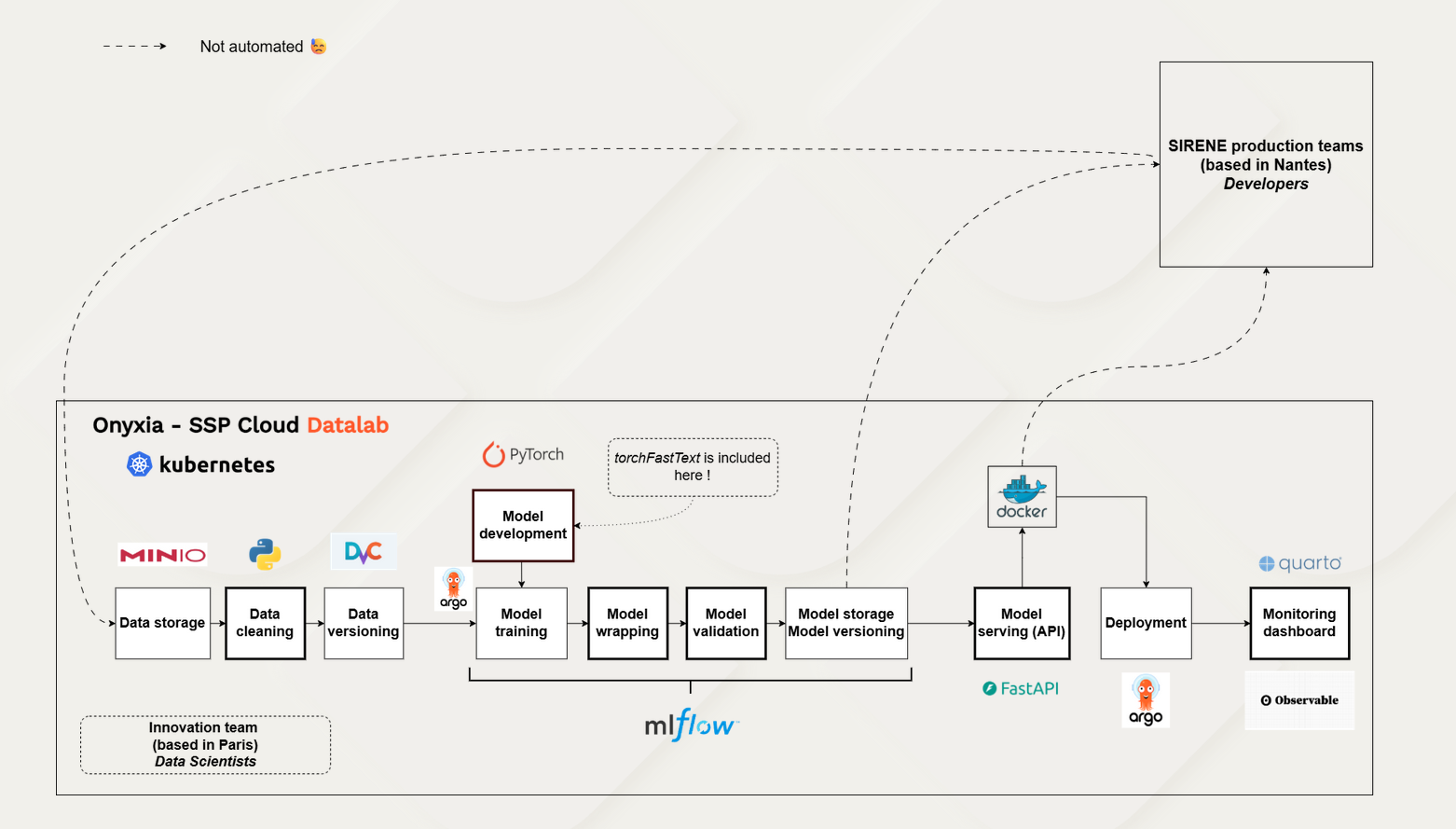
| Détail du projet | L’Insee dispose d’un classifieur en production - TorchTextClassifiers - entraîné sur 2,7 millions d’observations étiquetées selon la nomenclature européenne des activités économiques NACE 2.0. La révision de cette nomenclature vers la version 2.1 impose de réentraîner ce classifieur sur de nouvelles données labellisées. Une table de correspondance officielle permet de retraiter automatiquement les codes univoques (correspondance 1-à-1 entre les anciens codes et les nouveaux codes de la NACE), mais 52 % du corpus implique des codes « multivocaux » - un ancien code pouvant correspondre à plusieurs nouveaux codes (2 à 5 en général, mais plus de 30 dans certains cas extrêmes), ce qui représente environ 1,4 million d’observations impossibles à retraiter manuellement. Le projet développe une méthode de réétiquetage automatique par LLM pour résoudre ce problème structurel, récurrent lors de toute révision de nomenclature (NACE, COICOP, ISCO…). |
| Acteurs | Insee |
| Approche | La méthode développée est appelée RBAG (Rule-Based Augmented Generation) : le LLM ne génère pas librement un code parmi les 732 catégories NACE 2.1 (ce qui produirait des hallucinations), mais choisit parmi les seuls codes candidats fournis par la table de correspondance officielle, enrichis des notes explicatives NACE 2.1. La réponse est structurée (JSON) et un ensemble de trois modèles open-source (Qwen3-235B MoE, Qwen3-235B MoE en mode thinking, Gemma4-27B MoE) est utilisé avec vote majoritaire. L’ensemble du pipeline est orchestré sur le SSP Cloud via Argo Workflows. |
| Résultats du projet | Sur un benchmark de ~30 000 observations annotées par ~25 experts NACE, l’ensemble de LLMs atteint 78 % de précision. Le classifieur TorchTextClassifiers réentraîné sur le corpus semi-synthétique (~2,3 millions de labellisations) atteint ~80 % de précision sur NACE 2.1, soit des performances équivalentes à celles du classifieur NACE 2.0, validant l’approche par train-set semi-synthétique. Une comparaison avec une approche RAG pure (sans table de correspondance) montre un écart de ~10 points en défaveur du RAG. |
| Produits et documentation du projet | Présentation à l’ISI Regional Statistics Conference 2026, Malte - slides disponibles en ligne |
| Code du projet | Dépôt disponible sur GitHub |