GDP Tracker: a tool for continuous economic forecasting
Models of machine learning for real-time forecasting (nowcasting) to feed INSEE’s economic analyses
1 Jan 2022
| Recoding NACE 2.0 to NACE 2.1 with LLMs | |
|---|---|
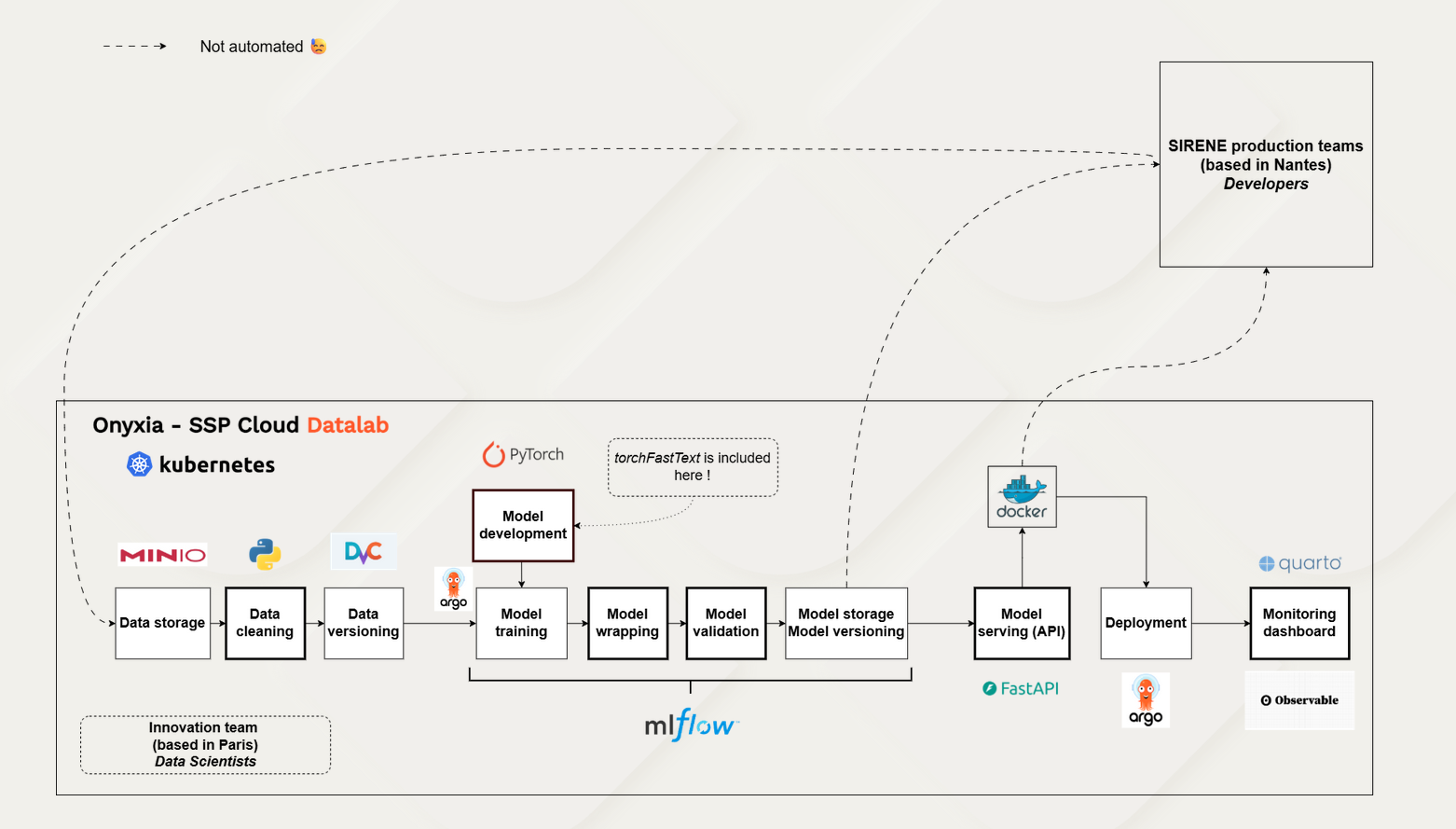
| Project details | INSEE operates a production classifier - TorchTextClassifiers - trained on 2.7 million observations labelled under the European economic activity nomenclature NACE 2.0. The revision of this nomenclature to version 2.1 requires retraining the classifier on new labelled data. An official correspondence table handles univocal codes (1-to-1 mapping between old and new NACE codes), but 52% of the training corpus involves “multivocal” codes - one old code corresponding to several new codes (typically 2 to 5, but more than 30 in some extreme cases) - representing approximately 1.4 million observations that cannot be manually relabelled. The project develops an automated LLM-based re-labelling method to solve this structural problem, which recurs at every nomenclature revision (NACE, COICOP, ISCO…). |
| Stakeholders | INSEE |
| Approach | The method is called RBAG (Rule-Based Augmented Generation): rather than asking the LLM to generate a code freely from all 732 NACE 2.1 categories (which would produce hallucinations), it selects from only the candidate codes provided by the official correspondence table, enriched with the NACE 2.1 explanatory notes. The output is structured (JSON) and a three-model open-source ensemble (Qwen3-235B MoE, Qwen3-235B MoE with thinking mode, Gemma4-27B MoE) is used with majority voting. The full pipeline is orchestrated on SSP Cloud via Argo Workflows. |
| Project results | On a benchmark of ~30,000 observations annotated by ~25 NACE experts, the LLM ensemble achieves 78% accuracy. The TorchTextClassifiers model retrained on the semi-synthetic corpus (~2.3 million labels) reaches ~80% accuracy on NACE 2.1, matching the performance of the original NACE 2.0 classifier - validating the semi-synthetic training set approach. A comparison with a pure RAG approach (without the correspondence table) shows a ~10-point gap in favour of RBAG. |
| Products and documentation | Presentation at the ISI Regional Statistics Conference 2026, Malta - slides available online |
| Project code | Repository available on GitHub |